Public data → assembly, annotation, MLST
Overview
- Download a readset from a public database
- Check the quality of the data and filter
- Assemble the reads into a draft genome
- Find antibiotic resistance genes
- Annotate the genome
- Find the sequence type (the MLST)
Background
Sequencing reads (readsets) for more than 100,000 isolates are available on public molecular sequence databases (GenBank/ENA/DDJB):
- Most of these have been produced using the Illumina sequencing platform.
- Most of these have no corresponding draft assembly.
Not all readsets are of high quality:
- There may be insufficient reads (usually ~x20 is the minimum read coverage needed).
- The reads could be from a mixed colony.
- The classification could be incorrect (both genus and species).
It is VERY important to check that what you find in the readset makes sense!
Import data
- Go to your Galaxy instance.
-
Set up a new History for this Activity.
- In the History panel, click on the cog icon, select
Create New . - A new empty history should appear; click on
Unnamed history and re-name it (e.g. ENA Activity).

- In the History panel, click on the cog icon, select
-
Choose an accession number.
- If you are working on this tutorial in a workshop: assign yourself a readset from the table of isolates provided. Put your name in Column B. The accession number for the readset that relates to each isolate is located in Column A. ERR019289 will be used in this demonstration.
- Alternatively, use accession number ERR019289. This is Vibrio cholerae.
-
In Galaxy, go to the Tools panel on the left, select
Get Data → EBI SRA .- This causes the ENA website to open.
- Enter the accession number in the ENA search bar.
-
(The search may find reads under Experiment and Run. If so, click on the Accession number under “Run”.)
-
Find the column called
Fastq files (galaxy) . Click onFile 1 .
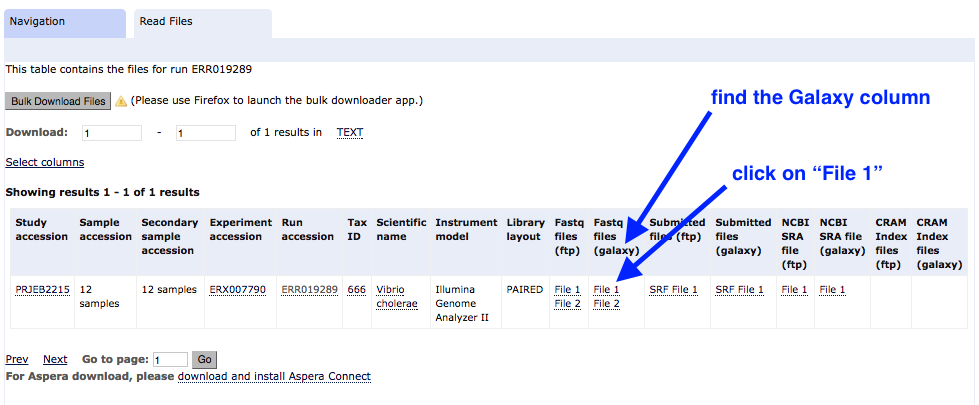
This file will download to your Galaxy history, and will return you to the Galaxy page.
-
Repeat the above steps for
Get Data → EBI SRA and downloadFile 2 . -
The files should now be in your Galaxy history.
- Click on the pencil icon next to File 1.
- Re-name it
ERR019289_1.fastq.gz .Save - Change the datatype to fastqsanger (note: not fastqCsanger).
Save
- Re-name it
- Repeat for File 2 (name it
ERR019289_2.fastq.gz ).
Evaluate quality
We will run FastQC on the pair of fastq files.
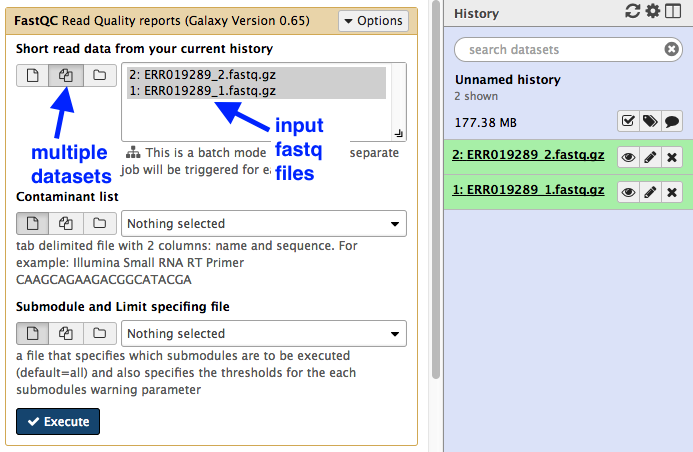
- In the Galaxy tools panel, go to
NGS Analysis: NGS QC and manipulation: FastQC . - Choose the
Multiple datasets icon and then select bothfastq files. - Your Galaxy window should look like this:
- Click
Execute - The output (4 files) will appear at the top of your Galaxy history.
- Click on the eye icon next to
FastQC on data 1: Web page - Scroll through the results. Take note of the maximum read length (e.g. 54 bp).
Trim
In this step we will remove adapters and trim low-quality sequence from the reads.
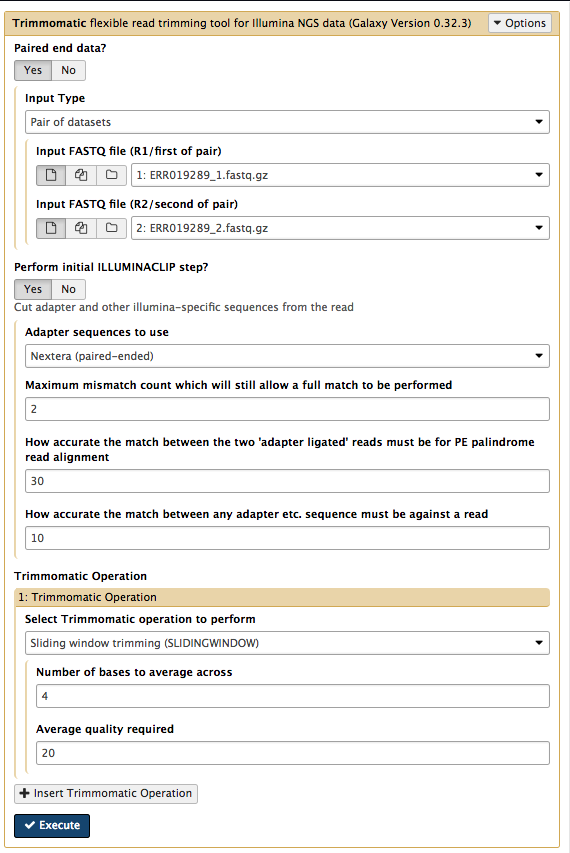
- In the Galaxy tools panel, go to
NGS Analysis: NGS QC and manipulation: Trimmomatic - Leave settings as they are except for:
Input FASTQ file R1 - check this is File 1Input FASTQ file R2 - check this is File 2
- Under
Perform initial ILLUMINACLIP step choose Yes- Under
Adapter sequences to use choose Nextera(paired-ended) - This trims particular adapters from the sequences.
- Under
- Under
Trimmomatic Operation leave the settings as they are.- We will use the average quality across a 4-base sliding window to identify and delete bad sequence (and the flanking bases to the start or end of the sequences - whichever is nearest to the patch of poor quality sequence)
Your tool interface should look like this:
- Click
Execute
There are four output files.
- Because trimmomatic might have trimmed some reads to zero, there are now some reads reads with no pair. These are in the unpaired output files. These can be deleted (with the cross button).
- Re-name the other two output files, e.g. as
ERRxxxxx_T1.fastq.gz &ERRxxxxx_T2.fastq.gz . These properly paired fastq files will be the input for the Spades assembly.
Assemble
We will assemble the trimmed reads.
In the left hand tools panel, go to
Leave the parameters as their defaults except:
Careful correction? NoKmers to use, separated by commas: 21,33,51- chosen kmers must be shorter than the maximum read length (see the FastQC output: sequence length)
Coverage Cutoff: Off- using a coverage cutoff might cause a problem if there are high-copy-number plasmids
Forward reads: ERR019289_T1.fastq.gzReverse reads: ERR019289_T2.fastq.gz
Your tool interface should look like this:
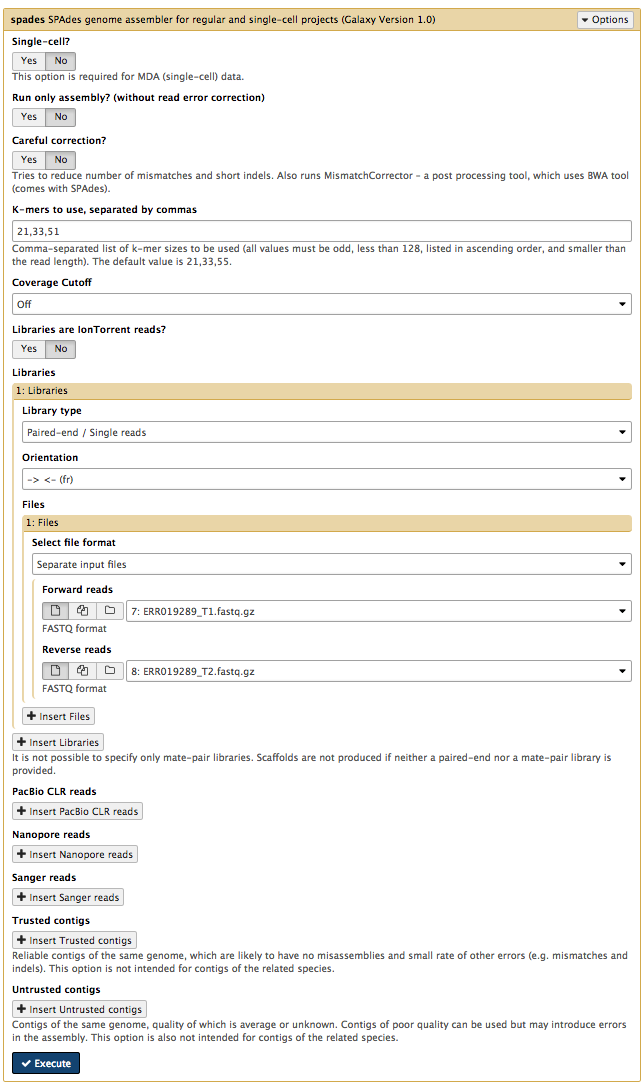
- Click
Execute
There are five output files.
SPAdes contigs (fasta) &SPAdes scaffolds (fasta) : The draft genome assembly. (These should be identical with the conditions used here.)SPAdes contig stats &SPAdes scaffold stats : A list of all the contigs and sizes in each of these files.SPAdes log : A summary of the assembly run.
Rename
Check the size of your draft genome sequence
- If you only have a few contigs, you can estimate the size from the
SPAdes contig stats file by adding together the contig sizes. - Alternatively, go to
NGS Common Toolsets: Fasta Statistics and input theSPAdes contigs (fasta) file. ClickExecute . The output will show the draft genome size next tonum_bp .
Compare your assembly size to others of the same species
- Go to the NCBI website: Genome
- Next to
Genome , enter the name of your species; e.g. Vibrio cholerae. - Click on
Genome ASsembly and Annotation report - View the table. Click on the
Size column to sort by size. (Check for additional pages at the bottom right.) - Is your assembly size similar?
Find antibiotic resistance genes
Now that we have our draft genome sequence, we can search for particular genes.
- We will use the tool called ABRicate to find antibiotic resistance genes in the genome.
- ABRicate uses a database of these genes called ResFinder.
In the tools panel, go to
- For
Select fasta file chooseSPAdes contigs (fasta) or whatever you renamed it (e.g. ERR019289.fasta). - Click
Execute .
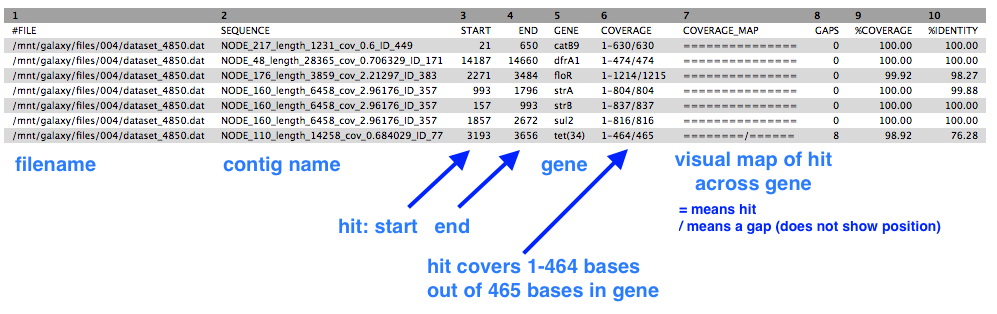
There is one output file. Click on the eye icon to view.
- This shows a table with one line for each antibiotic resistance gene found, in which contig, at which position, and the % coverage.
Find the sequence type (MLST)
Bacterial samples (isolates) are often assigned a “sequence type”. This is a number that defines the particular combination of alleles in that isolate, e.g. ST248.
- Because several genes (loci) are used, this is termed Multi-Locus Sequence Typing (MLST).
- There are different MLST schemes for different groups of bacteria.
In the tools panel, go to
- Under
input_file choose chooseSPAdes contigs (fasta) or whatever you renamed it (e.g. ERR019289.fasta). - Note: a specific MLST scheme can be specified if you wish, but by default all schemes are searched
- Click
Execute .
There is one output file. Click on the eye icon to view.
- There is a one line output.
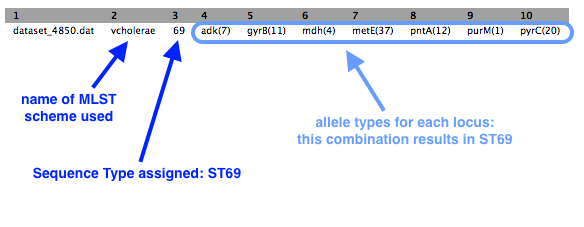
Some symbols are used to describe missing or inexact matches to alleles:
- n: Exact intact allele
- ~n : Novel allele similar to n
- n,m : Multiple alleles
- - : Allele missing
Annotate
We have found a list of resistance genes in the draft sequence, but we can also annotate the whole genome to find all the genes present.
In the tools panel, go to
Set the following parameters (leave everything else unchanged):
Contigs to annotate :SPAdes contigs (fasta) (or equivalent)Locus tag prefix (–locustag) : PForce GenBank/ENA/DDJB compliance (–compliant) : NoSequencing Centre ID (–centre) : V- Click
Execute
There are several output files:
-
gff : the master annotation in GFF format, containing both sequences and annotations -
gbk : a standard GenBank file derived from the master .gff. If the input to prokka was a multi-FASTA, then this will be a multi-GenBank, with one record for each sequence -
fna : nucleotide FASTA file of the input contig sequences -
faa : protein FASTA file of the translated CDS sequences -
ffn : nucleotide FASTA file of all the annotated sequences, not just CDS -
sqn : an ASN1 format “Sequin” file for submission to GenBank. It needs to be edited to set the correct taxonomy, authors, related publication, etc. -
fsa : nucleotide FASTA file of the input contig sequences, used by “tbl2asn” to create the .sqn file. It is mostly the same as the .fna file, but with extra Sequin tags in the sequence description lines -
tbl : Feature Table file, used by “tbl2asn” to create the .sqn file -
err : unacceptable annotations - the NCBI discrepancy report -
log : contains all the output that Prokka produced during its run -
txt : statistics relating to the annotated features found
Tabulate
If you are working on this tutorial as part of a class workshop:
- Go to the table of isolates and add information about genome size, GC content, and number of contigs.
Next
- View the annotated genome in Artemis or JBrowse.