Differential Gene Expression
Keywords: differential gene expression, DGE, RNA, RNA-Seq, transcriptomics, Degust, voom, limma, Galaxy, Microbial Genomics Virtual Laboratory.
This tutorial is about differential gene expression in bacteria, using Galaxy tools and Degust (web).
Background
Differential Gene Expression (DGE) is the process of determining whether any genes were expressed at a different level between two conditions. For example, the conditions could be wildtype versus mutant, or two growth conditions. Usually multiple biological replicates are done for each condition - these are needed to separate variation within the condition from that between the conditions.
Learning Objectives
At the end of this tutorial you should be able to:
- Align RNA-Seq data to a reference genome
- Count transcripts for each sample
- Perform statistical analysis to obtain a list of differentially expressed genes
- Visualize and interpret the results
Input data: reads and reference
RNA-Seq reads
A typical experiment will have 2 conditions each with 3 replicates, for a total of 6 samples.
- Our RNA-seq reads are from 6 samples in
FASTQ format.- We have single-end reads; so one file per sample.
- Data could also be paired-end reads, and there would be two files per sample.
- These have been reduced to 1% of their original size for this tutorial.
- The experiment used the bacteria E. coli grown in two conditions.
- Files labelled “LB” are the wildtype
- Files labelled “MG” have been exposed to 0.5% αMG - alpha methyglucoside (a sugar solution).
Reference genome
The reference genomes is in
- The
FASTA file contains the DNA sequence(s) that make up the genome; e.g. the chromosome and any plasmids. - The
GTF file lists the coordinates (position) of each feature. Commonly-annotated features are genes, transcripts and protein-coding sequences.
Upload files to Galaxy
- Log in to your Galaxy server.
- In the
History pane, click on the cog icon, and select
icon, and select Import from File (at the bottom of the list). - Under
Archived History URL paste: https://swift.rc.nectar.org.au:8888/v1/AUTH_377/public/Microbial_tutorials/Galaxy-History-BacterialDGE.tar.gz - In the
History pane, click on the view icon and find the uploaded history.
icon and find the uploaded history.- (This may take a minute. Refresh the page.)
- Click
Switch to that history, thenDone . - The files should now be ready to use in your current History pane.
Align reads to reference
The RNA-Seq reads are fragmented and are not complete transcripts. To determine the transcripts from which the reads originated (and therefore, to which gene they correspond) we can map them to a reference genome.
In Galaxy:
- Go to
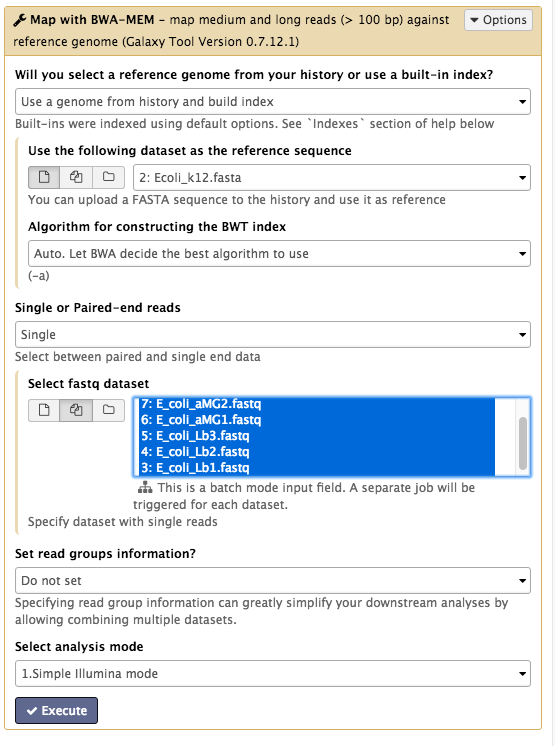
Tools → NGS Analysis → NGS: Mapping → Map with BWA-MEM - Under
Will you select a reference genome from your history or use a built-in index? : Use a genome from history and build index Use the following dataset as the reference sequence :Ecoli_k12.fasta Single or Paired-end reads : singleSelect fastq dataset :- Click on the
Multiple Datasets icon in centre - Select all 6
FASTQ files (they turn blue; use side-scroll bar to check all have been selected) - This will map each set of reads to the reference genome
- Click on the
Your tool interface should look like this:
- Click
Execute - Click
Refresh in the history pane to see if the analysis has finished. -
Output: 6
bam files of reads mapped to the reference genome. -
Re-name the output files:
- These are called
Map with BWA-MEM on data x and data x . - Click on the pencil icon next to each of these and re-name them as their sample name (e.g. LB1, LB2 etc.).
- Click
Save .
- These are called
Count reads per gene
We now need to count how many reads overlap with particular genes. The information about gene names is from the annotations in the GTF file.
In Galaxy:
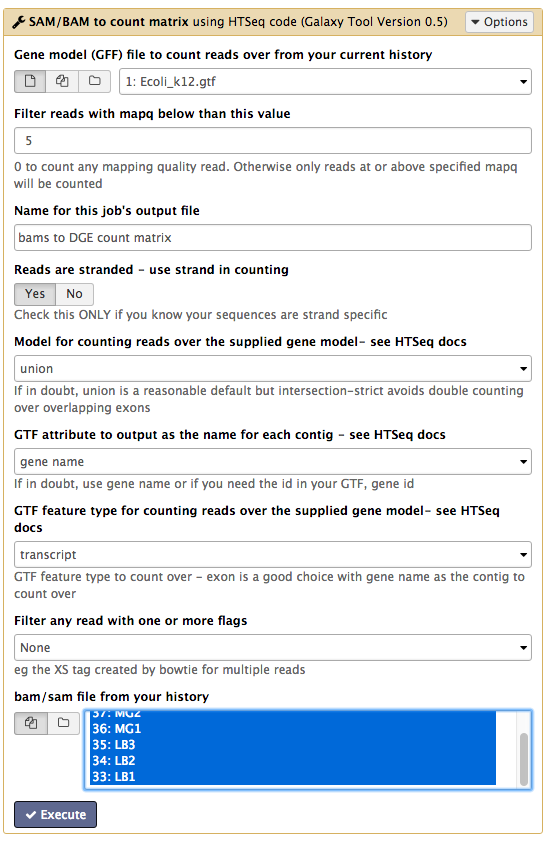
- Go to
Tools → NGS Analysis → NGS: RNA Analysis → SAM/BAM to count matrix .- Note: Don’t select the tool called htseq-count. The SAM/BAM to count matrix also uses that tool but allows an input of multiple bam files, which is what we want.
- For
Gene model (GFF) file to count reads over from your current history , select theGTF file. - For
Reads are stranded select Yes (box turns dark grey) - For
GTF feature type for counting reads… select transcript. - For
bam/sam file from your history choose the 6bam files.
Your tool interface should look like this:
- Click
Execute - Click
Refresh in the history pane to see if the analysis has finished.
Output:
- There is one output file:
bams to DGE count matrix . - Click on the file name to expand the information in the History pane.
- Click on the file
 icon underneath to download it to your computer for use later on in this tutorial.
icon underneath to download it to your computer for use later on in this tutorial. - Click on the eye icon to see this file.
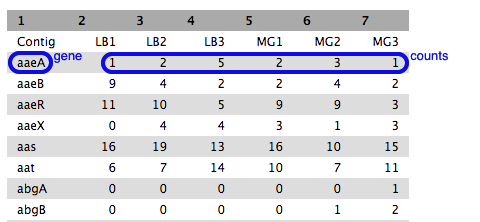
- Each row is a gene (or feature) and each column is a sample, with counts against each gene.
- Have a look at how the counts vary between samples, per gene.
- We can’t just compare the counts directly; they need to be normalized before comparison, and this will be done as part of the DGE analysis in the next step.
DGE in Degust
Degust is a tool on the web that can analyse the counts files produced in the step above, to test for differential gene expression.
(Degust can also display the results from DGE analyses performed elsewhere.)
Upload counts file
Go to the Degust web page. Click
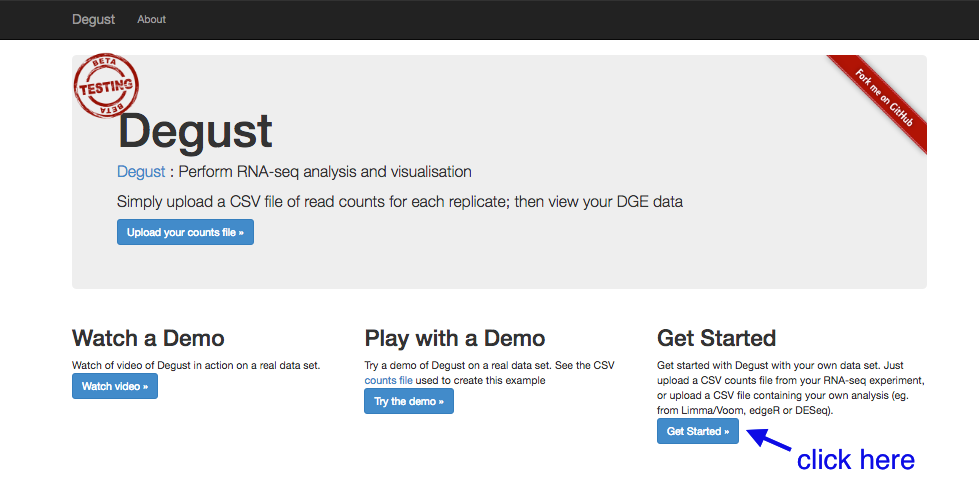
- Click on
Choose File . - Select the
htseq output file. tabular (that you previously downloaded to your computer from Galaxy) and clickOpen . - Click
Upload .
A Configuation page will appear.
- For
Name type DGE in E coli - For
Info columns select Contig - For
Analyze server side leave box checked. - For
Min read count put 10. - Click
Add condition - Add a condition called “Control” and select the LB columns.
- Add a condition called “Treament” and select the MG columns.
Your Configuration page should look like this:
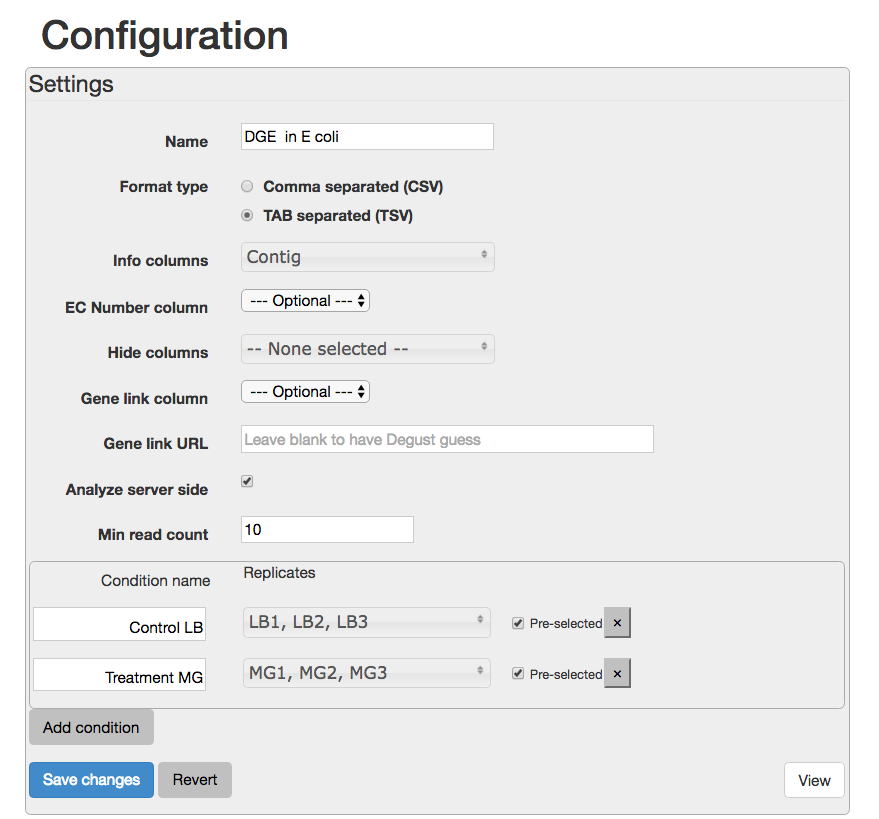
Save changes View - this brings up the Degust viewing window.
Overview of Degust sections
- Top black panel with
Configure settings at right. - Left: Conditions: Control and Treatment.
- Left: Method selection for DGE.
- Top centre: Plots, with options at right.
- When either of the expression plots are selected, a heatmap appears below.
- A table of genes (or features); expression in treatment relative to control (Treatment column); and significance (FDR column).
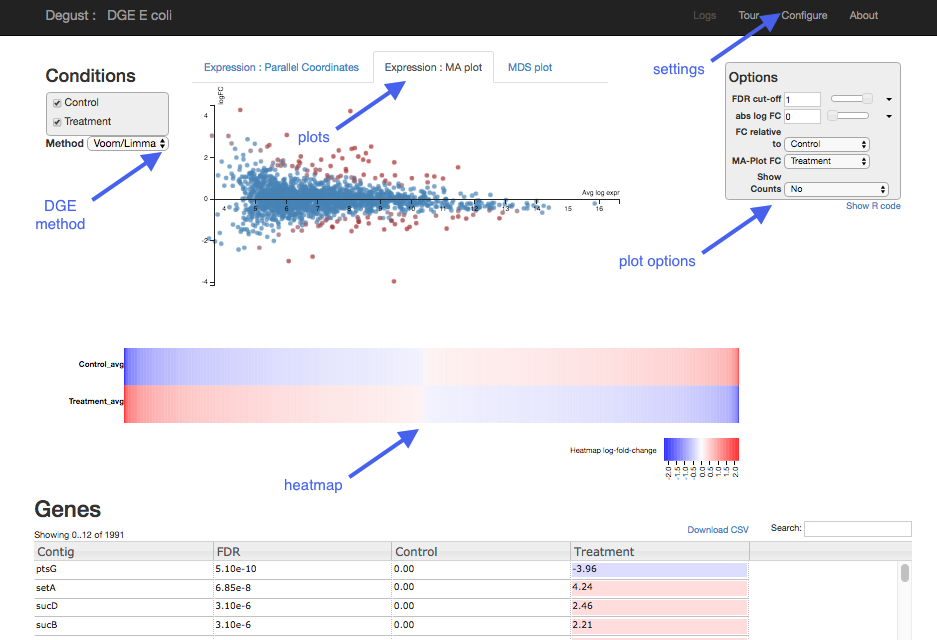
Analyze gene expression
- Under
Method , make sure thatVoom/Limma is selected. - Click
Apply . This runs Voom/Limma on the uploaded counts.
MDS plot
First, look at the MDS plot.
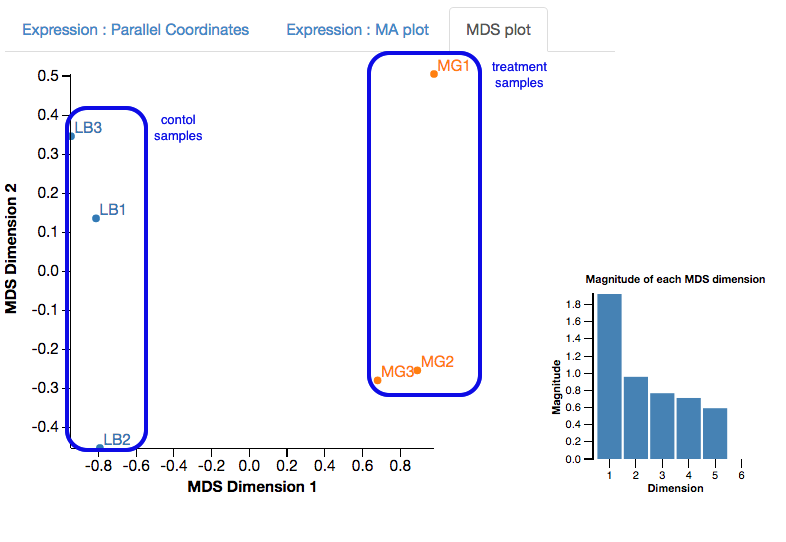
- This is a multidimensional scaling plot which represents the variation between samples.
- Ideally:
- All the LB samples would be close to each other
- All the MG samples would be close to each other
- The LB and MG groups would be far apart
- The x-axis is the dimension with the highest magnitude. The control/treatment samples should be split along this axis.
- Our LB samples are on the left and the MG samples are on the right, which means they are well separated on their major MDS dimension, which looks correct.
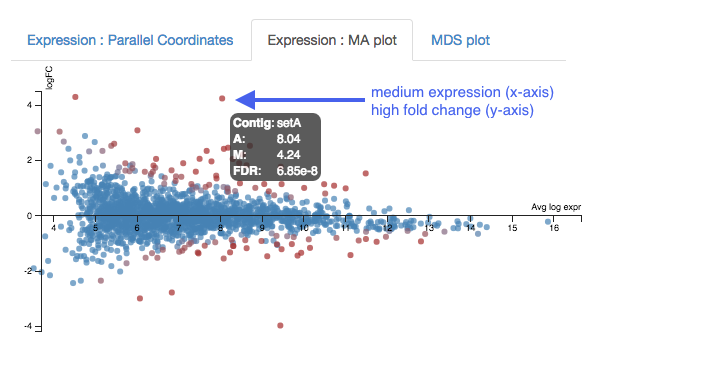
Expression - MA plot
Each dot shows the change in expression in one gene.
- The average expression (over both condition and treatment samples) is represented on the x-axis.
- Plot points should be symmetrical around the x-axis.
- We can see that many genes are expressed at a low level, and some are highly expressed.
- The fold change is represented on the y axis.
- If expression is significantly different between treatment and control, the dots are red. If not, they are blue. (In Degust, significant means FDR <0.05).
- At low levels of gene expression (low values of the x axis), fold changes are less likely to be significant.
Click on the dot to see the gene name.
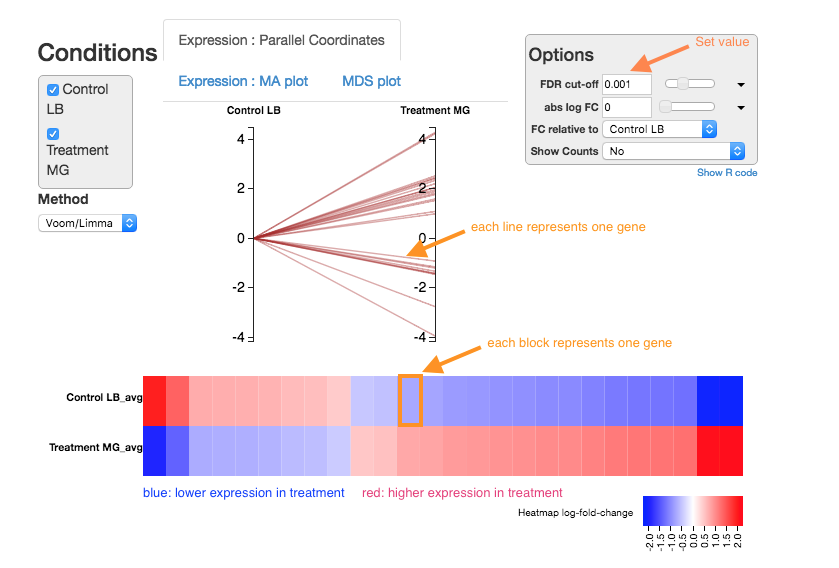
Expression - Parallel Coordinates and heatmap
Each line shows the change in expression in one gene, between control and treatment.
- Go to
Options at the right.- For
FDR cut-off set at 0.001. - This is a significance level (an adjusted p value). We will set it quite low in this example, to ensure we only examine key differences.
- For
-
Look at the Parallel Coordinates plot. There are two axes:
- Left: Control: Gene expression in the control samples. All values are set at zero.
- Right: Treatment Gene expression in the treatment samples, relative to expression in the control.
-
The blocks of blue and red underneath the plot are called a heatmap.
- Each block is a gene. Click on a block to see its line in the plot above.
- Look at the row for the Treatment. Relative to the control, genes expressed more are red; genes expressed less are blue.
Note:
- for an experiment with multiple treatments, the various treatment axes can be dragged to rearrange. There is no natural order (such as a time series).
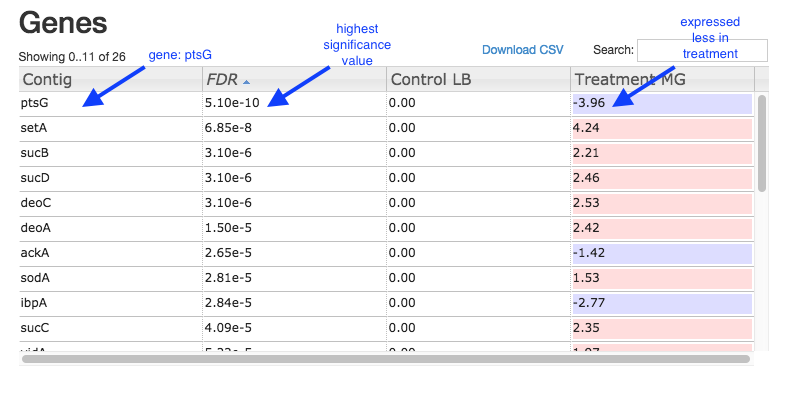
Table of genes
- Contig: names of genes. Note that gene names are sometimes specific to a species, or they may be only named as a locus ID (a chromosomal location specified in the genome annotation).
- FDR: False Discovery Rate. This is an adjusted p value to show the significance of the difference in gene expression between two conditions. Click on column headings to sort. By default, this table is sorted by FDR.
- Control and Treatment: log2(Fold Change) of gene expression. The default display is of fold change in the treatment relative to the control. Therefore, values in the “Control” column are zero. This can be changed in the
Options panel at the top right. - In some cases, a large fold change will be meaningful but in others, even a small fold change can be important biologically.
Table of genes and expression:
DGE in Galaxy
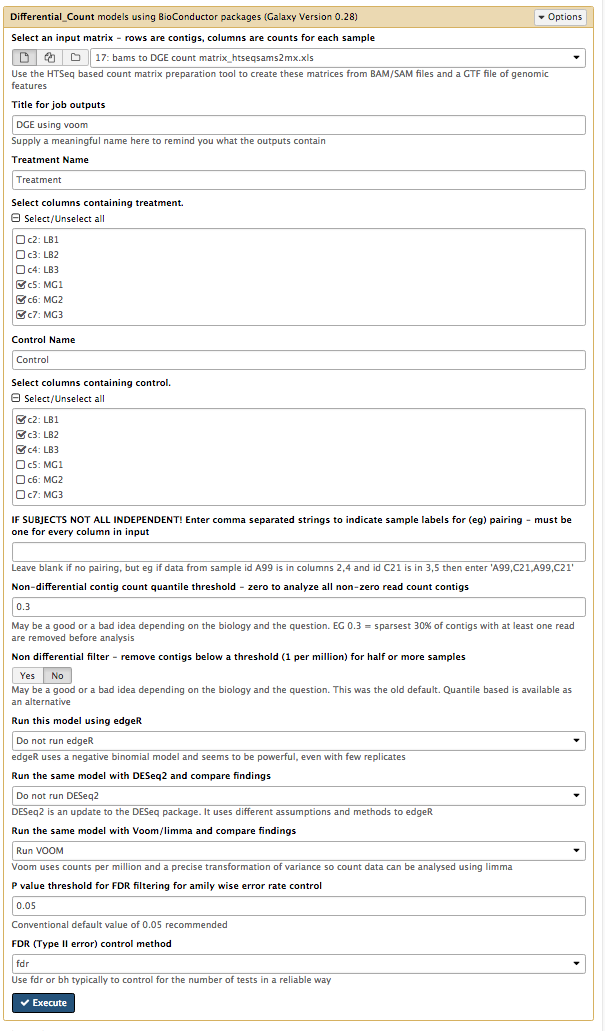
Differential gene expression can also be analyzed in Galaxy. The input is the count matrix produced by a tool such as HTSeq-Count (see section above: “Count reads per gene”).
- Go to
Tools → NGS Analysis → NGS: RNA Analysis → Differential Count models - This has options to use edgeR, DESeq, or Voom. Here we will use Voom.
- For
Select an input matrix choose thecount matrix file generated in the previous step. - For
Title for job outputs enter DGE using voom. - For
Select columns containing treatment tick boxes for the MG samples. - For
Select columns containing control tick boxes for the LB samples. - Under
Run this model using edgeR choose Do not run edgeR. - Under
Run the same model with DESeq2 and compare findings choose Do not run DESeq2. - Under
Run the same model with Voom/limma and compare findings choose Run VOOM.
Your tool interface should look like this:
- Click
Execute .
There are two output files.
View the file called
- Scroll down to “VOOM log output” and “#VOOM top 50”.
- The “Contig” column has the gene names.
- Look at the “adj.P.Val” column. This is an adjusted p value to show the significance of the gene expression difference, accounting for the effect of multiple testing. Also known as False Discovery Rate. The table is ordered by the values in this column.
- Look at the “logFC” column. This is log2(Fold Change) of relative gene expression between the treatment samples and the control samples.
View the file called
- This is a list of all the genes that had transcripts mapped, and associated statistics.
What next?
To learn more about the differentially-expressed genes:
- Go to the NCBI website.
- Under
All Databases , click on Gene - Enter the gene name in the search bar; e.g. ptsG
- Click on the first result that matches the species (e.g. in this case, E. coli).
- This provides information about the gene, and may also show further references (e.g. in this case, a link to the EcoGene resource).
Some of the most (statistically) significant differentially-expressed genes in this experiment are:
- ptsG: a glucose-specific transporter.
- setA: a sugar efflux transporter; is induced by glucose-phosphate stress.
- sucD: the alpha subunit of the the gene for succinyl-CoA synthetase; involved in ATP production.
- sucB: a component of the 2-oxoglutarate dehydrogenase complex; catalyzes a step in the Krebs cycle.
- deoC: 2-deoxyribose-5-phosphate aldolase; binds selenium; may be involved in selenium transport.
Next steps: Investigate the biochemical pathways involving the genes of interest.